开发
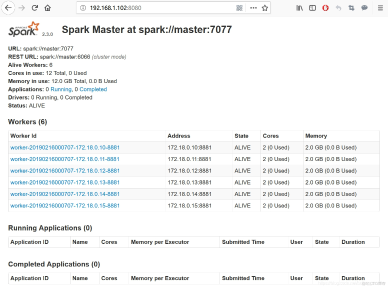
spark实战之:分析维基百科网站统计数据(java版)
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 在《寻找海量数据集用于大数据开发实战(维基百科网站统计
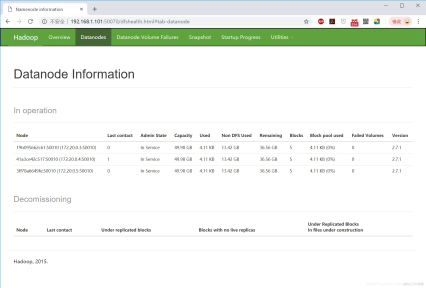
docker下,极速搭建spark集群(含hdfs集群)
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 搭建spark和hdfs的集群环境会消耗一些时间和精力
环境变量与进程地址空间理解
写在前面 这个博客主要谈一下环境变量和程序地址空间,其中程序地址空间可能有点不好理解,但是这个可以帮助我们解决前面我们遗留的一些问题,以后我们几乎都要和程序地址空间打交道,很重要.当然,前面的环境变量
第一个spark应用开发详解(java版)
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos WordCount是大数据学习最好的入门demo,今天
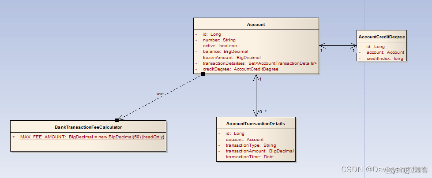
领域驱动设计系列贫血模型和充血模型
面向过程的设计方式(贫血模型) 假设现在有一个银行支付系统项目,其中的一个重要的业务用例是账户转账业务。系统使用迭代的方式进行开发,在1.0版本中,该用例的功能需求非常简单,事件流描述如下: 主事件流
kettle庖丁解牛第34篇之常用转换组件之Add XML
引言 上一篇文章中,讲解的是:我工作中遇到的一个实际案例,我们要周期性的从上游mysql数据库中抽取数据到本地hive库中,每次抽取的是最近6个月的数据。hive中的目标表是按月做的分区,把最近6个月
MMA安装及使用优化
1.背景 公司自建的Hadoop集群,后期使用阿里的Maxcompute,就需要迁移数据到新环境中,阿里提供众多的迁移方案,在经过我们的实践后,最终选择了MMA,迁移数据Hive到Maxcompute
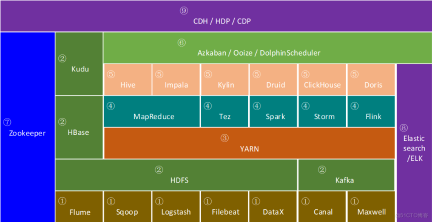
一文看懂大数据生态圈完整知识体系【大数据技术及架构图解实战派】
一文看懂大数据生态圈完整知识体系 徐葳 随着大数据行业的发展,大数据生态圈中相关的技术也在一直迭代进步,作者有幸亲身经历了国内大数据行业从零到一的发展历程,通过本文希望能够帮助大家快速构建大数据生态圈

推荐系统-协同过滤在Spark中的实现
作者:vivo 互联网服务器团队-Tang Shutao 现如今推荐无处不在,例如抖音、淘宝、京东App均能见到推荐系统的身影,其背后涉及许多的技术。本文以经典的协同过滤为切入点,重点介绍了被工业界广

clickhouse 20.x 与prometheus + grafana+ckman的集成(三)
标签(空测试用例格分隔):clickhouse 系列 一:clickhouse 监控集成 1.1:clickhouse 与grafana 的集成 为grafana加载 支持的clickhouse 的监
Scala 基础 (三):运算符和流程控制
(文章目录) 一、运算符 Scala中的运算符和Java中的运算符基本相同。 算术运算 + - * / % ,+和-在一元运算表中示正号和负号,在二元运算中表示加和减。 /表示整除,只保留整数部分舍弃
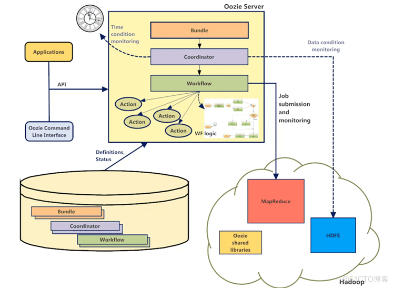
大数据Hadoop之——任务调度器Oozie(Oozie环境部署)
一、概述 Oozie是一个基于工作流引擎的开源框架,依赖于MapReduce来实现,是一个管理 Apache Hadoop 作业的工作流调度系统。是由Cloudera公司贡献给Apache的,它能够提
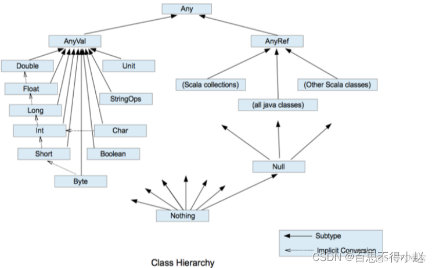
Scala 基础 (二):变量和数据类型
(文章目录) 一、变量和常量 如何定义? var 变量名 [: 变量类型] = 初始值 val 常量名 [: 常量类型] = 初始值 举个栗子: var a: Int = 10;
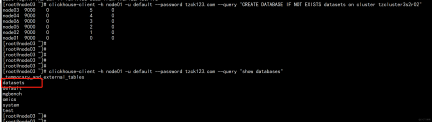
clickhouse 20.x 分布式表测试与chproxy的部署(二)
标签(空测试用例格分隔):clickhouse 系列 一: clickhouse20.x的分布式表测 1.1:clickhosue 分布式表创建 准备测试文件: 参考官网 https://clic
数据湖(十七):Flink与Iceberg整合DataStream API操作
Flink与Iceberg整合DataStream API操作 目前Flink支持使用DataStream API 和SQL API 方式实时读取和写入Iceberg表,建议大家使用SQL API 方